Language-Conditioned Navigation Affordance Prediction under Occlusion
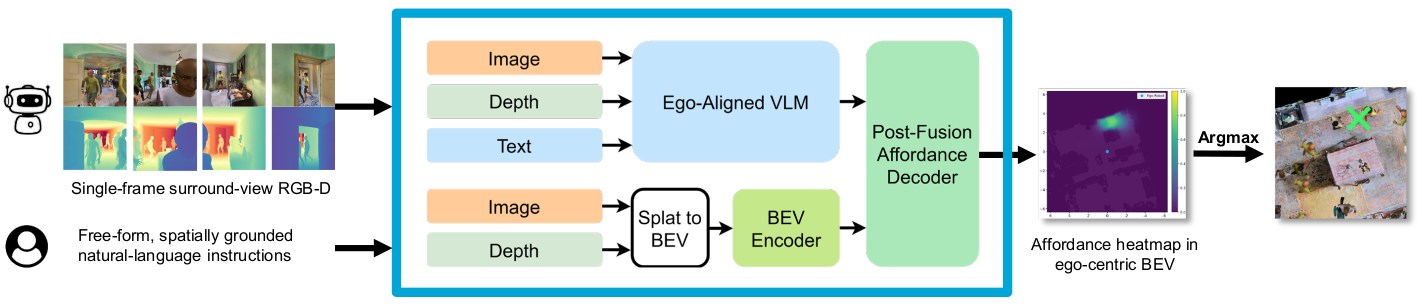
Abstract
Language-conditioned local navigation requires a robot to infer a nearby traversable target location from its current observation and an open-vocabulary, relational instruction. Existing vision-language spatial grounding methods usually rely on vision-language models (VLMs) to reason in image space, producing 2D predictions tied to visible pixels. As a result, they struggle to infer target locations in occluded regions, typically caused by furniture or moving humans. To address this issue, we propose BEACON, which predicts an ego-centric Bird's-Eye View (BEV) affordance heatmap over a bounded local region including occluded areas. Given an instruction and surround-view RGB-D observations from four directions around the robot, BEACON predicts the BEV heatmap by injecting spatial cues into a VLM and fusing the VLM's output with depth-derived BEV features. Using an occlusion-aware dataset built in the Habitat simulator, we conduct detailed experimental analysis to validate both our BEV space formulation and the design choices of each module. Our method improves the accuracy averaged across geodesic thresholds by 22.74 percentage points over the state-of-the-art image-space baseline on the validation subset with occluded target locations.
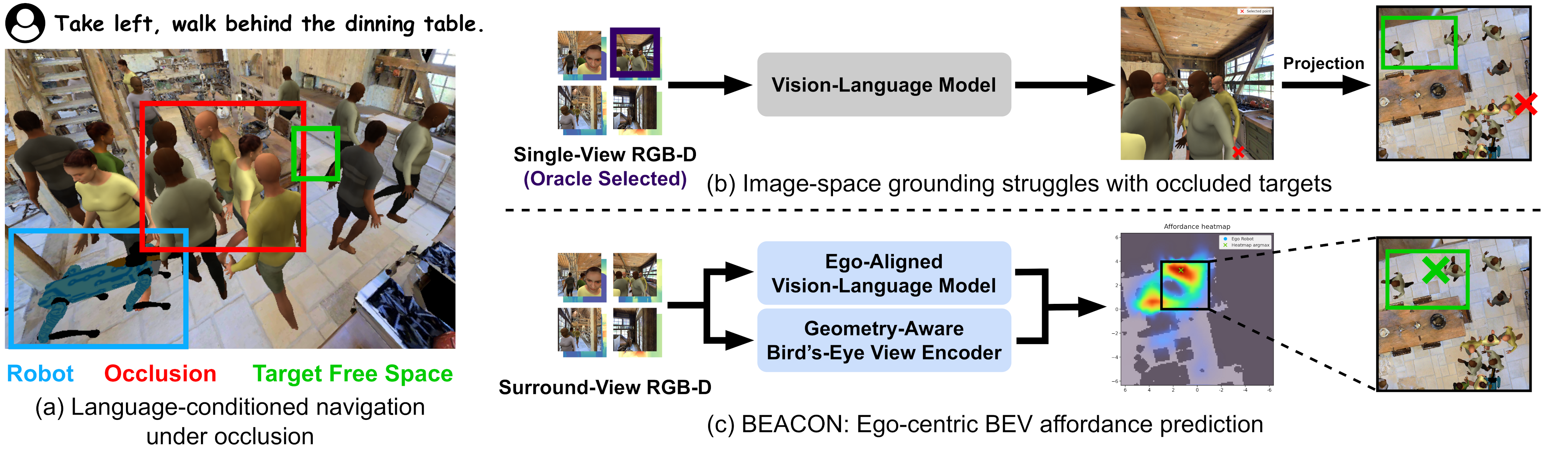
Method Overview
BEACON overview. Stage 1 performs auto-derived ego-centric instruction tuning with ego-centric 3D position encoding to train the Ego-Aligned VLM. Stage 2 initializes the Ego-Aligned VLM weights from Stage 1, combines the resulting instruction-conditioned output with Geometry-Aware BEV features, and predicts an ego-centric BEV navigation affordance heatmap via a Post-Fusion Affordance Decoder. The two stages use different supervision signals, and inference selects the navigation target by taking the argmax.
Results
Using an occlusion-aware dataset built in the Habitat simulator, we conduct detailed experimental analysis to validate both our BEV space formulation and the design choices of each module.
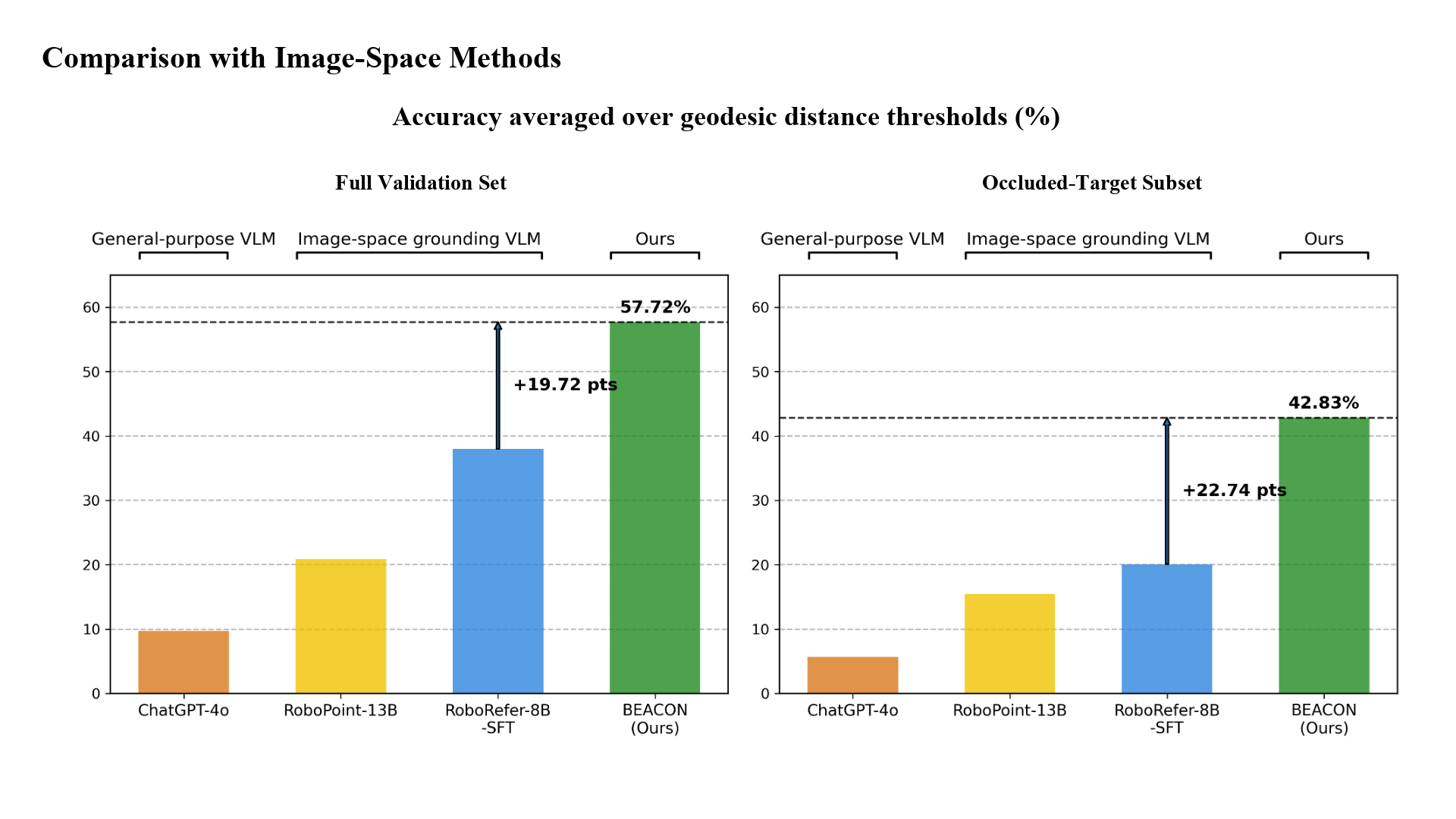
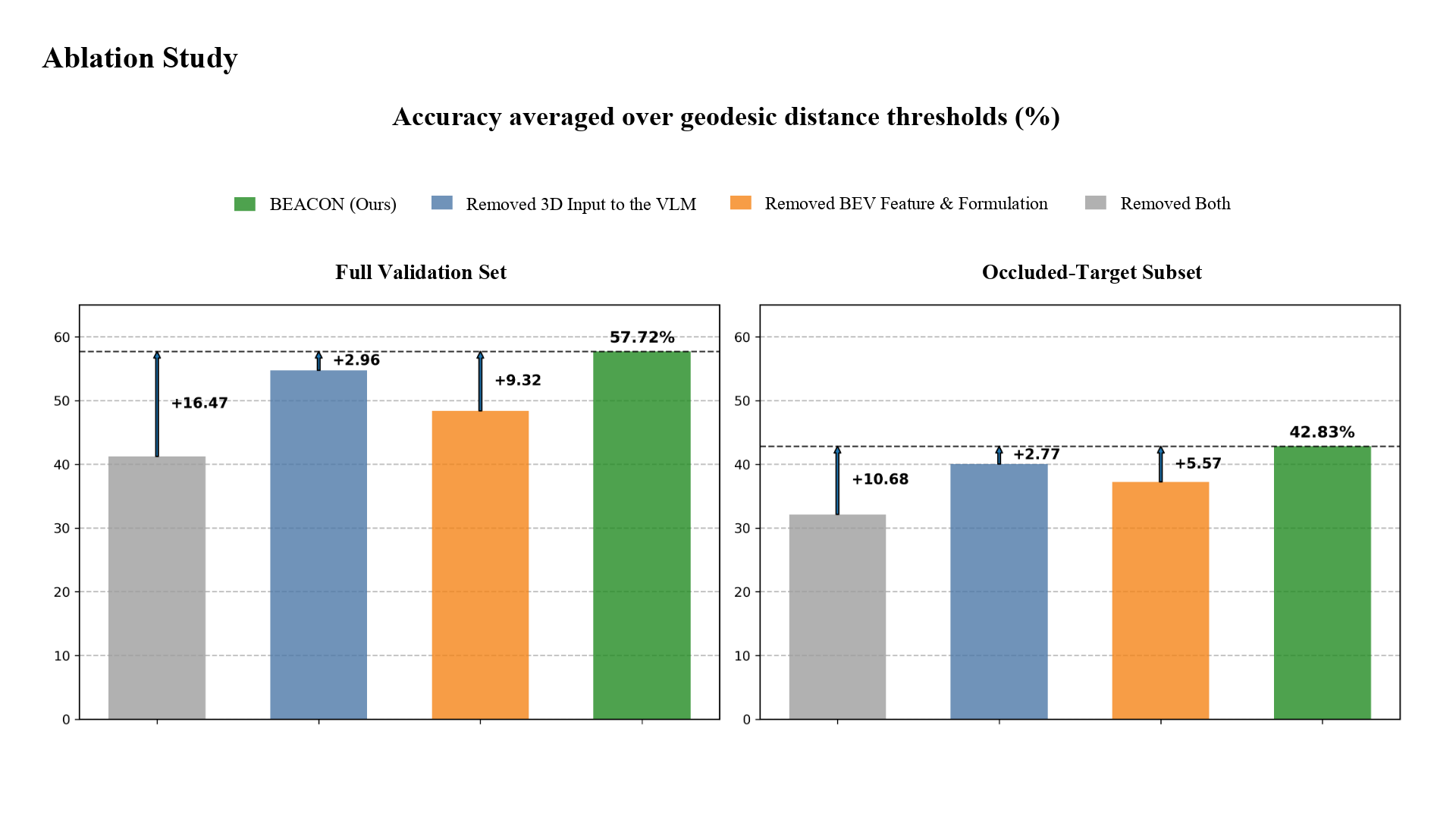
Our method improves the accuracy averaged across geodesic thresholds by 22.74 percentage points over the state-of-the-art image-space baseline on the validation subset with occluded target locations.

These two examples show BEACON correctly grounding the instruction under heavy occlusion. Compared with image-space baselines, it can infer plausible target regions even when they are occluded, by predicting affordance in BEV space beyond visible pixels.

These two examples illustrate typical errors: confusion about the referred landmark or spatial relation, and ambiguity in how far the robot should proceed. Even when it fails, the predicted target still remains spatially feasible.
Conclusions
In this work, we propose BEACON, a VLM-based BEV affordance predictor for local navigation target prediction conditioned on an open-vocabulary instruction. In unseen environments in the Habitat simulator, BEACON shows consistent gains over prior image-space baselines, with the largest improvements on the occluded-target subset. While image-space baselines struggle with occluded cues or targets, BEACON outputs an ego-centric BEV affordance heatmap that yields more accurate targets and substantially fewer non-traversable predictions. These improvements are not simply the result of adding task-specific supervision, nor are they explained solely by post-hoc snapping to free space; instead, BEACON improves both Euclidean target accuracy and traversable-target validity. Extensive ablations further validate the importance of ego-aligned 3D cues and BEV-space design choices.