Real-world experimental results
From left to right, top to bottom, the videos below show 1) Full-pose manipulation with 3 MAVs, 2) Robustness against complete in-flight failure of one MAV, 3) Full-pose manipulation with 4 MAVs, 4) Robstuness against unknown disturbances (15.4% of original load mass) placed in the load, which are free to move around, 5) Robustness against hetereogeneous agent setups, where one hacked MAV is commanded around with a different controller, and 6) Trajectory tracking of a figure-8. Note that our method is not trained for trajectory tracking. The entire pipeline is executed onboard, with the policies running at 100 Hz, and the low-level controller running at 300 Hz. Importantly, we achieve (near) constant computation time as we scale up the number of agents, and achieve similar tracking performance to a centralized NMPC benchmark.
Abstract
This paper presents the first decentralized method to enable real-world 6-DoF manipulation of a cable-suspended load using a team of Micro-Aerial Vehicles (MAVs). Our method leverages multi-agent reinforcement learning (MARL) to train an outer-loop control policy for each MAV. Unlike state-of-the-art controllers that utilize a centralized scheme, our policy does not require global states, inter-MAV communications, nor neighboring MAV information. Instead, agents communicate implicitly through load pose observations alone, which enables high scalability and flexibility. It also significantly reduces computing costs during inference time, enabling onboard deployment of the policy. In addition, we introduce a new action space design for the MAVs using linear acceleration and body rates. This choice, combined with a robust low-level controller, enables reliable sim-to-real transfer despite significant uncertainties caused by cable tension during dynamic 3D motion. We validate our method in various real-world experiments, including full-pose control under load model uncertainties, showing setpoint tracking performance comparable to the state-of-the-art centralized method. We also demonstrate cooperation amongst agents with heterogeneous control policies, and robustness to the complete in-flight loss of one MAV.
Method overview
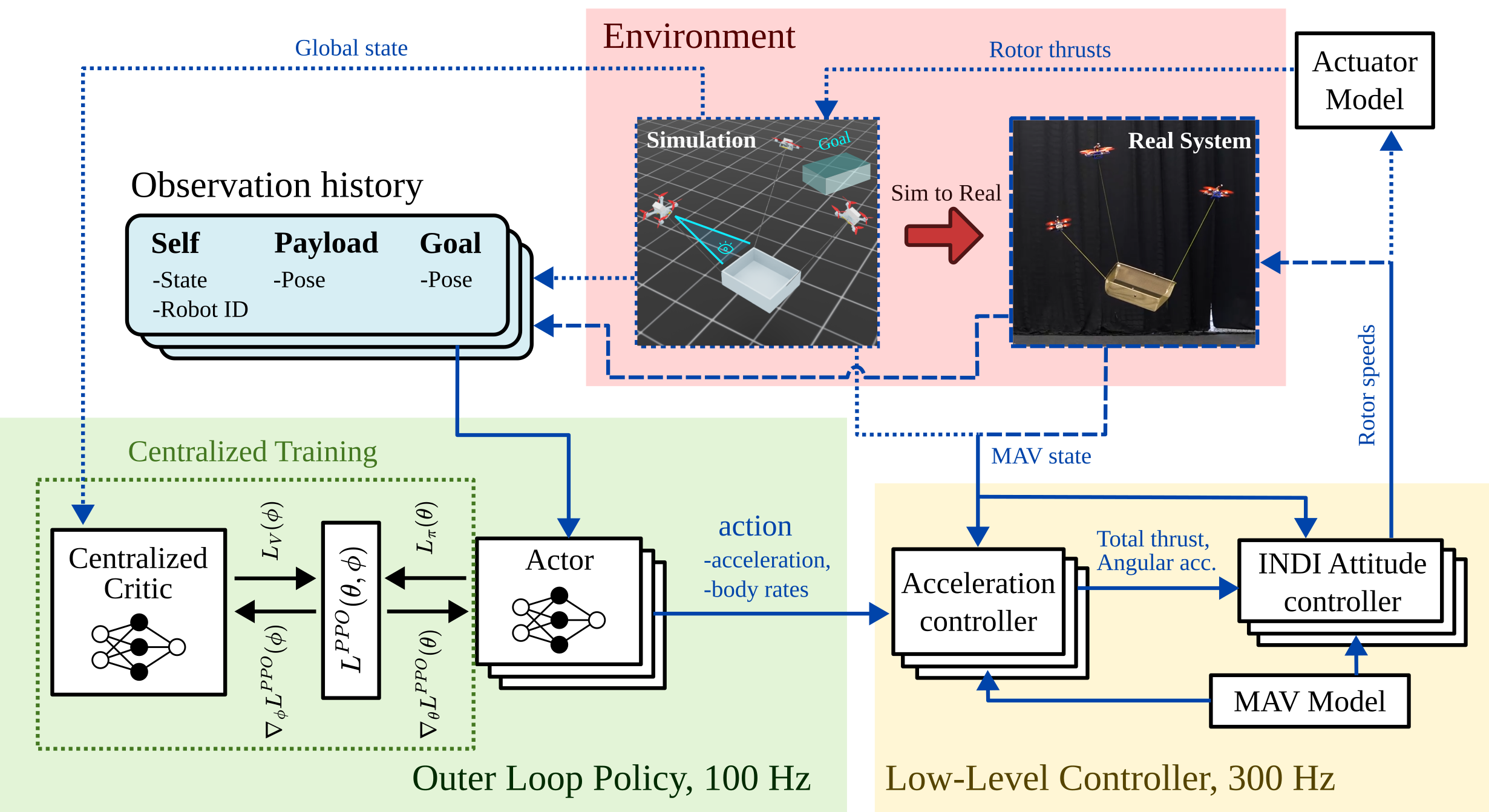
Overview of our method. Dotted lines indicate components only for training; dashed lines indicate those only for real-system deployment; solid lines for both. Our method utilizes MARL to train an outer-loop control policy, which generates reference accelerations and body rates for the low-level controller in real-time based on local observations of the ego-MAV state, its robot ID, payload- and goal pose. The low-level controller, including an INDI attitude controller, tracks these references based on the MAV model and accelerometer measurements. The privileged full state is observed by the centralized critic during training, which is discarded at execution time. Collected experience is shared across actors to update the parameters of a shared policy. This enables training to be centralized while execution remains decentralized, allowing each agent to run the policy independently onboard after zero-shot transfer from simulation to the real world.
Conclusion
We introduced a decentralized method using MARL that allows for full-pose control of a cable-suspended load using three MAVs without any inter-MAV communication or neighboring MAV information. The policy is computationally tractable, scales (near) constant with the number of agents, and executes entirely onboard. We proposed a novel action space of accelerations and body rates (ACCBR) along with a robust low-level controller and showcase zero-shot transfer from simulation to real-world deployment. Extensive testing with real MAVs shows that the setpoint tracking performance of our method is comparable to that of the state-of-the-art centralized NMPC, despite being fully decentralized and having significantly lower computation time. Our method demonstrates robustness against unknown disturbances, heterogeneous agents, and even the complete in-flight failure of one MAV. We attribute this resilience to two key factors: 1) closed-loop reference tracking by the low-level controller, which maintains stability despite perturbations, 2) decentralized policy independence, where local agents operate without dependence on neighboring states, preventing cascading failures. Our work shows promising results to enable scalable and robust cooperative aerial manipulation with minimal onboard sensing and no internal communications required.
Decentralized Real-Time Planning for Multi-UAV Cooperative Manipulation via Imitation Learning
Shantnav Agarwal,
Javier Alonso-Mora,
Sihao Sun.
In IEEE Int. Symposium on Multi-Robot & Multi-Agent Systems (MRS),
2025.
Existing approaches for transporting and manipulating cable-suspended loads using multiple UAVs along reference trajectories typically rely on either centralized control architectures or reliable inter-agent communication. In this work, we propose a novel machine learning based method for decentralized kinodynamic planning that operates effectively under partial observability and without inter-agent communication. Our method leverages imitation learning to train a decentralized student policy for each UAV by imitating a centralized kinodynamic motion planner with access to privileged global observations. The student policy generates smooth trajectories using physics-informed neural networks that respect the derivative relationships in motion. During training, the student policies utilize the full trajectory generated by the teacher policy, leading to improved sample efficiency. Moreover, each student policy can be trained in under two hours on a standard laptop. We validate our method in both simulation and real-world environments to follow an agile reference trajectory, demonstrating performance comparable to that of centralized approaches.
Agile and Cooperative Aerial Manipulation of a Cable-Suspended Load
Sihao Sun,
Xuerui Wang,
Dario Sanalitro,
Antonio Franchi,
Marco Tognon,
Javier Alonso-Mora.
In Science Robotics,
2025.
Quadrotors can carry slung loads to hard-to-reach locations at high speed. Since a single quadrotor has limited payload capacities, using a team of quadrotors to collaboratively manipulate a heavy object is a scalable and promising solution. However, existing control algorithms for multi-lifting systems only enable low-speed and low-acceleration operations due to the complex dynamic coupling between quadrotors and the load, limiting their use in time-critical missions such as search and rescue. In this work, we present a solution to significantly enhance the agility of cable-suspended multi-lifting systems. Unlike traditional cascaded solutions, we introduce a trajectory-based framework that solves the whole-body kinodynamic motion planning problem online, accounting for the dynamic coupling effects and constraints between the quadrotors and the load. The planned trajectory is provided to the quadrotors as a reference in a receding-horizon fashion and is tracked by an onboard controller that observes and compensates for the cable tension. Real-world experiments demonstrate that our framework can achieve at least eight times greater acceleration than state-of-the-art methods to follow agile trajectories. Our method can even perform complex maneuvers such as flying through narrow passages at high speed. Additionally, it exhibits high robustness against load uncertainties and does not require adding any sensors to the load, demonstrating strong practicality.
Visually-Guided Motion Planning for Autonomous Driving from Interactive Demonstrations
R. Perez-Dattari,
B. Brito,
O. de Groot,
J. Kober,
J. Alonso-Mora.
In IFAC Engineering Applications of Artificial Intelligence Journal,
2022.
The successful integration of autonomous robots in real-world environments strongly depends on their ability to reason from context and take socially acceptable actions. Current autonomous navigation systems mainly rely on geometric information and hard-coded rules to induce safe and socially compliant behaviors. Yet, in unstructured urban scenarios these approaches can become costly and suboptimal. In this paper, we introduce a motion planning framework consisting of two components: a data-driven policy that uses visual inputs and human feedback to generate socially compliant driving behaviors (encoded by high-level decision variables), and a local trajectory optimization method that executes these behaviors (ensuring safety). In particular, we employ Interactive Imitation Learning to jointly train the policy with the local planner, a Model Predictive Controller (MPC), which results in safe and human-like driving behaviors. Our approach is validated in realistic simulated urban scenarios. Qualitative results show the similarity of the learned behaviors with human driving. Furthermore, navigation performance is substantially improved in terms of safety, i.e., number of collisions, as compared to prior trajectory optimization frameworks, and in terms of data-efficiency as compared to prior learning-based frameworks, broadening the operational domain of MPC to more realistic autonomous driving scenarios.
Learning Interaction-Aware Guidance for Trajectory Optimization in Dense Traffic Scenarios
B. Brito,
A. Agarwal,
J. Alonso-Mora.
In IEEE Transactions on Intelligent Transportation Systems (T-ITS),
2022.
Autonomous navigation in dense traffic scenarios remains challenging for autonomous vehicles (AVs) because the intentions of other drivers are not directly observable and AVs have to deal with a wide range of driving behaviors. To maneuver through dense traffic, AVs must be able to reason how their actions affect others (interaction model) and exploit this reasoning to navigate through dense traffic safely. This paper presents a novel framework for interaction-aware motion planning in dense traffic scenarios. We explore the connection between human driving behavior and their velocity changes when interacting. Hence, we propose to learn, via deep Reinforcement Learning (RL), an interaction-aware policy providing global guidance about the cooperativeness of other vehicles to an optimization-based planner ensuring safety and kinematic feasibility through constraint satisfaction. The learned policy can reason and guide the local optimization-based planner with interactive behavior to pro-actively merge in dense traffic while remaining safe in case the other vehicles do not yield. We present qualitative and quantitative results in highly interactive simulation environments (highway merging and unprotected left turns) against two baseline approaches, a learning-based and an optimization-based method. The presented results demonstrate that our method significantly reduces the number of collisions and increases the success rate with respect to both learning-based and optimization-based baselines.
Decentralized Probabilistic Multi-Robot Collision Avoidance Using Buffered Uncertainty-Aware Voronoi Cells
H. Zhu,
B. Brito,
J. Alonso-Mora.
In Autonomous Robots (AURO),
2022.
In this paper, we present a decentralized and communication-free collision avoidance approach for multi-robot systems that accounts for both robot localization and sensing uncertainties. The approach relies on the computation of an uncertainty-aware safe region for each robot to navigate among other robots and static obstacles in the environment, under the assumption of Gaussian-distributed uncertainty. In particular, at each time step, we construct a chance-constrained buffered uncertainty-aware Voronoi cell (B-UAVC) for each robot given a specified collision probability threshold. Probabilistic collision avoidance is achieved by constraining the motion of each robot to be within its corresponding B-UAVC, i.e. the collision probability between the robots and obstacles remains below the specified threshold. The proposed approach is decentralized, communication-free, scalable with the number of robots and robust to robots’ localization and sensing uncertainties. We applied the approach to single-integrator, double-integrator, differential-drive robots, and robots with general nonlinear dynamics. Extensive simulations and experiments with a team of ground vehicles, quadrotors, and heterogeneous robot teams are performed to analyze and validate the proposed approach.
Where to go next: Learning a Subgoal Recommendation Policy for Navigation in Dynamic Environments
B. Brito,
M. Everett,
J. P. How,
J. Alonso-Mora.
In , IEEE Robotics and Automation Letters (RA-L),
2021.
Robotic navigation in environments shared with other robots or humans remains challenging because the intentions of the surrounding agents are not directly observable and the environment conditions are continuously changing. Local trajectory optimization methods, such as model predictive control (MPC), can deal with those changes but require global guidance, which is not trivial to obtain in crowded scenarios. This letter proposes to learn, via deep Reinforcement Learning (RL), an interaction-aware policy that provides long-term guidance to the local planner. In particular, in simulations with cooperative and non-cooperative agents, we train a deep network to recommend a subgoal for the MPC planner. The recommended subgoal is expected to help the robot in making progress towards its goal and accounts for the expected interaction with other agents. Based on the recommended subgoal, the MPC planner then optimizes the inputs for the robot satisfying its kinodynamic and collision avoidance constraints. Our approach is shown to substantially improve the navigation performance in terms of number of collisions as compared to prior MPC frameworks, and in terms of both travel time and number of collisions compared to deep RL methods in cooperative, competitive and mixed multiagent scenarios.
Learning Interaction-Aware Trajectory Predictions for Decentralized Multi-Robot Motion Planning in Dynamic Environments
H. Zhu,
F. Claramunt,
B. Brito,
J. Alonso-Mora.
In , IEEE Robotics and Automation Letters (RA-L),
2021.
This letter presents a data-driven decentralized trajectory optimization approach for multi-robot motion planning in dynamic environments. When navigating in a shared space, each robot needs accurate motion predictions of neighboring robots to achieve predictive collision avoidance. These motion predictions can be obtained among robots by sharing their future planned trajectories with each other via communication. However, such communication may not be available nor reliable in practice. In this letter, we introduce a novel trajectory prediction model based on recurrent neural networks (RNN) that can learn multi-robot motion behaviors from demonstrated trajectories generated using a centralized sequential planner. The learned model can run efficiently online for each robot and provide interaction-aware trajectory predictions of its neighbors based on observations of their history states. We then incorporate the trajectory prediction model into a decentralized model predictive control (MPC) framework for multi-robot collision avoidance. Simulation results show that our decentralized approach can achieve a comparable level of performance to a centralized planner while being communication-free and scalable to a large number of robots. We also validate our approach with a team of quadrotors in real-world experiments.
Scenario-Based Trajectory Optimization in Uncertain Dynamic Environments
O. de Groot,
B. Brito,
L. Ferranti,
D. Gavrila,
J. Alonso-Mora.
In , IEEE Robotics and Automation Letters (RA-L),
2021.
We present an optimization-based method to plan the motion of an autonomous robot under the uncertainties associated with dynamic obstacles, such as humans. Our method bounds the marginal risk of collisions at each point in time by incorporating chance constraints into the planning problem. This problem is not suitable for online optimization outright for arbitrary probability distributions. Hence, we sample from these chance constraints using an uncertainty model, to generate "scenarios", which translate the probabilistic constraints into deterministic ones. In practice, each scenario represents the collision constraint for a dynamic obstacle at the location of the sample. The number of theoretically required scenarios can be very large. Nevertheless, by exploiting the geometry of the workspace, we show how to prune most scenarios before optimization and we demonstrate how the reduced scenarios can still provide probabilistic guarantees on the safety of the motion plan. Since our approach is scenario based, we are able to handle arbitrary uncertainty distributions. We apply our method in a Model Predictive Contouring Control framework and demonstrate its benefits in simulations and experiments with a moving robot platform navigating among pedestrians, running in real-time.
Curvature Aware Motion Planning with Closed-Loop Rapidly-exploring Random Trees
B. van den Berg,
B. Brito,
M. Alirezaei,
J. Alonso-Mora.
In IEEE Intelligent Vehicles Symposium (IV),
2021.
The road's geometry strongly influences the path planner's performance, critical for autonomous navigation in high-speed dynamic scenarios (e.g., highways). Hence, this paper introduces the Curvature-aware Rapidly-exploring Random Trees (CA-CL-RRT), whose planning performance is invariant to the road's geometry. We propose a transformation strategy that allows us to plan on a virtual straightened road and then convert the planned motion to the curved road. It is shown that the proposed approach substantially improves path planning performance on curved roads as compared to prior RRT-based path planners. Moreover, the proposed CA-CL-RRT is combined with a Local Model Predictive Contour Controller (LMPCC) for path tracking while ensuring collision avoidance through constraint satisfaction. We present quantitative and qualitative performance results in two navigation scenarios: dynamic collision avoidance and structured highway driving. The results demonstrate that our proposed navigation framework improves the path quality on curved highway roads and collision avoidance with dynamic obstacles.
Online Trajectory Planning and Control of a MAV Payload System in Dynamic Environments
N. D. Potdar,
G. C. H. D. de Croon,
J. Alonso-Mora.
In Springer Autonomous Robots,
2020.
Micro Aerial Vehicles (MAVs) can be used for aerial transportation in remote and urban spaces where portability can be exploited to reach previously inaccessible and inhospitable spaces. Current approaches for path planning of MAV swung payload system either compute conservative minimal-swing trajectories or pre-generate agile collision-free trajectories. However, these approaches have failed to address the prospect of online re-planning in uncertain and dynamic environments, which is a prerequisite for real-world deployability. This paper describes an online method for agile and closed-loop local trajectory planning and control that relies on Non-Linear Model Predictive Control and that addresses the mentioned limitations of contemporary approaches. We integrate the controller in a full system framework, and demonstrate the algorithm’s effectiveness in simulation and in experimental studies. Results show the scalability and adaptability of our method to various dynamic setups with repeatable performance over several complex tasks that include flying through a narrow opening and avoiding moving humans.
Trajectory Optimization and Situational Analysis Framework for Autonomous Overtaking with Visibility Maximization
H. Andersen,
J. Alonso-Mora,
Y.H. Eng,
D. Rus,
M. Ang.
In IEEE Transactions on Intelligent Vehicles (T-IV),
2020.
In this article we present a trajectory generation method for autonomous overtaking of unexpected obstacles in a dynamic urban environment. In these settings, blind spots can arise from perception limitations. For example when overtaking unexpected objects on the vehicle's ego lane on a two-way street. In this case, a human driver would first make sure that the opposite lane is free and that there is enough room to successfully execute the maneuver, and then it would cut into the opposite lane in order to execute the maneuver successfully. We consider the practical problem of autonomous overtaking when the coverage of the perception system is impaired due to occlusion. Safe trajectories are generated by solving, in real-time, a non-linear constrained optimization, formulated as a receding horizon planner that maximizes the ego vehicle's visibility. The planner is complemented by a high-level behavior planner, which takes into account the occupancy of other traffic participants, the information from the vehicle's perception system, and the risk associated with the overtaking maneuver, to determine when the overtake maneuver should happen. The approach is validated in simulation and in experiments in real world traffic.
Social-VRNN: One-Shot Multi-modal Trajectory Prediction for Interacting Pedestrians
B. Brito,
H. Zhu,
W. Pan,
J. Alonso-Mora.
In Proc. 2020 Conference on Robot Learning (CoRL),
2020.
Prediction of human motions is key for safe navigation of autonomous robots among humans. In cluttered environments, several motion hypotheses may exist for a pedestrian, due to its interactions with the environment and other pedestrians. Previous works for estimating multiple motion hypotheses require a large number of samples which limits their applicability in real-time motion planning. In this paper, we present a variational learning approach for interaction-aware and multi-modal trajectory prediction based on deep generative neural networks. Our approach can achieve faster convergence and requires significantly fewer samples comparing to state-of-the-art methods. Experimental results on real and simulation data show that our model can effectively learn to infer different trajectories. We compare our method with three baseline approaches and present performance results demonstrating that our generative model can achieve higher accuracy for trajectory prediction by producing diverse trajectories.
Robust Vision-based Obstacle Avoidance for Micro Aerial Vehicles in Dynamic Environments
J. Liu,
H. Zhu,
J. Alonso-Mora.
In Proc. IEEE Int. Conf. on Robotics and Automation (ICRA),
2020.
In this paper, we present an on-board vision-based approach for avoidance of moving obstacles in dynamic environments. Our approach relies on an efficient obstacle detection and tracking algorithm based on depth image pairs, which provides the estimated position, velocity and size of the obstacles. Robust collision avoidance is achieved by formulating a chance-constrained model predictive controller (CC-MPC) to ensure that the collision probability between the micro aerial vehicle (MAV) and each moving obstacle is below a specified threshold. The method takes into account MAV dynamics, state estimation and obstacle sensing uncertainties. The proposed approach is implemented on a quadrotor equipped with a stereo camera and is tested in a variety of environments, showing effective on-line collision avoidance of moving obstacles.
Chance-constrained Collision Avoidance for MAVs in dynamic environments
H. Zhu,
J. Alonso-Mora.
In , IEEE Robotics and Automation Letters (RA-L),
2019.
Safe autonomous navigation of microair vehicles in cluttered dynamic environments is challenging due to the uncertainties arising from robot localization, sensing, and motion disturbances. This letter presents a probabilistic collision avoidance method for navigation among other robots and moving obstacles, such as humans. The approach explicitly considers the collision probability between each robot and obstacle and formulates a chance constrained nonlinear model predictive control problem (CCNMPC). A tight bound for approximation of collision probability is developed, which makes the CCNMPC formulation tractable and solvable in real time. For multirobot coordination, we describe three approaches, one distributed without communication (constant velocity assumption), one distributed with communication (of previous plans), and one centralized (sequential planning). We evaluate the proposed method in experiments with two quadrotors sharing the space with two humans and verify the multirobot coordination strategy in simulation with up to sixteen quadrotors.
Optimizing Multi-class Fleet Compositions for Shared Mobility-as-a-Service
A. Wallar,
W. Schwartig,
J. Alonso-Mora,
D. Rus.
In Proc. IEEE Int. Conf. on Intelligent Transportation Systems (ITSC),
2019.
Mobility-as-a-Service (MaaS) systems are transforming the way society moves. The introduction and adoption of pooled ride-sharing has revolutionized urban transit with the potential of reducing vehicle congestion, improving accessibility and flexibility of a city's transportation infrastructure. Recently developed algorithms can compute routes for vehicles in realtime for a city-scale volume of requests, as well as optimize fleet sizes for MaaS systems that allow requests to share vehicles. Nonetheless, they are not capable of reasoning about the composition of a fleet and their varying capacity classes. In this paper, we present a method to not only optimize fleet sizes, but also their multi-class composition for MaaS systems that allow requests to share vehicles. We present an algorithm to determine how many vehicles of each class and capacity are needed, where they should be initialized, and how they should be routed to service all the travel demand for a given period of time. The algorithm maximizes utilization while reducing the total number of vehicles and incorporates constraints on wait- times and travel-delays. Finally, we evaluate the effectiveness of the algorithm for multi-class fleets with pooled ride-sharing using 426,908 historical taxi requests from Manhattan and 187,243 downtown Singapore. We show fleets comprised of vehicles with smaller capacities can reduce the total travel delay by 10% in Manhattan whereas larger capacity fleets in downtown Singapore contribute to a 9% reduction in the total waiting time.
B-UAVC: Buffered Uncertainty-Aware Voronoi Cells for Probabilistic Multi-Robot Collision Avoidance
H. Zhu,
J. Alonso-Mora.
In Proc. 2nd IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS'19),
2019.
This paper presents B-UAVC, a distributed collision avoidance method for multi-robot systems that accounts for uncertainties in robot localization. In particular, Buffered Uncertainty-Aware Voronoi Cells (B-UAVC) are employed to compute regions where the robots can safely navigate. By computing a set of chance constraints, which guarantee that the robot remains within its B-UAVC, the method can be applied to non-holonomic robots. A local trajectory for each robot is then computed by introducing these chance constraints in a receding horizon model predictive controller. The method guarantees, under the assumption of normally distributed position uncertainty, that the collision probability between the robots remains below a specified threshold. We evaluate the proposed method with a team of quadrotors in simulations and in real experiments.
Optimizing Vehicle Distributions and Fleet Sizes for Mobility-on-Demand
A. Wallar,
J. Alonso-Mora,
D. Rus.
In Proc. IEEE Int. Conf. on Robotics and Automation (ICRA),
2019.
Mobility-on-demand (MoD) systems are revolutionizing urban transit with the introduction of ride-sharing. Such systems have the potential to reduce vehicle congestion and improve accessibility of a city's transportation infrastructure. Recently developed algorithms can compute routes for vehicles in real-time for a city-scale volume of requests while allowing vehicles to carry multiple passengers at the same time. However, these algorithms focus on optimizing the performance for a given fleet of vehicles and do not tell us how many vehicles are needed to service all the requests. In this paper, we present an offline method to optimize the vehicle distributions and fleet sizes on historical demand data for MoD systems that allow passengers to share vehicles. We present an algorithm to determine how many vehicles are needed, where they should be initialized, and how they should be routed to service all the travel demand for a given period of time. Evaluation using 23,529,740 historical taxi requests from one month in Manhattan shows that on average 2864 four passenger vehicles are needed to service all of the taxi demand in a day with an average added travel delay of 2.8 mins.
Distributed Multi-Robot Formation Splitting and Merging in Dynamic Environments
H. Zhu,
J. Juhl,
L. Ferranti,
J. Alonso-Mora.
In Proc. IEEE Int. Conf. on Robotics and Automation (ICRA),
2019.
This paper presents a distributed method for splitting and merging of multi-robot formations in dynamic environments with static and moving obstacles. Splitting and merging actions rely on distributed consensus and can be performed to avoid obstacles. Our method accounts for the limited communication range and visibility radius of the robots and relies on the communication of obstacle-free convex regions and the computation of an intersection graph. In addition, our method is able to detect and recover from (permanent and temporary) communication and motion faults. Finally, we demonstrate the applicability and scalability of the proposed method in simulations with up to sixteen quadrotors and real-world experiments with a team of four quadrotors.
SafeVRU: A Research Platform for the Interaction of Self-Driving Vehicles with Vulnerable Road Users
L. Ferranti,
B. Brito,
E. Pool,
Y. Zheng,
R. M. Ensing,
R. Happee,
B. Shyrokau,
J. Kooij,
J. Alonso-Mora,
D. M. Gavrila.
In Proc. IEEE Intelligent Vehicles Symposium,
2019.
This paper presents our research platform Safe VRU for the interaction of self-driving vehicles with Vulnerable Road Users (VRUs, i.e., pedestrians and cyclists). The paper details the design (implemented with a modular structure within ROS) of the full stack of vehicle localization, environment perception, motion planning, and control, with emphasis on the environment perception and planning modules. The environment perception detects the VRUs using a stereo camera and predicts their paths with Dynamic Bayesian Networks (DBNs), which can account for switching dynamics. The motion planner is based on model predictive contouring control (MPCC) and takes into account vehicle dynamics, control objectives (e.g., desired speed), and perceived environment (i.e., the predicted VRU paths with behavioral uncertainties) over a certain time horizon. We present simulation and real-world results to illustrate the ability of our vehicle to plan and execute collision-free trajectories in the presence of VRUs.
Distributed Formation Control in Dynamic Environments
J. Alonso-Mora,
E. Montijano,
T. Naegeli,
O. Hilliges,
M. Schweger,
D. Rus.
In , Autonomous Robots,
2018.
This paper presents a distributed method for formation control of a homogeneous team of aerial or ground mobile robots navigating in environments with static and dynamic obstacles. Each robot in the team has a finite communication and visibility radius and shares information with its neighbors to coordinate. Our approach leverages both constrained optimization and multi-robot consensus to compute the parameters of the multi-robot formation. This ensures that the robots make progress and avoid collisions with static and moving obstacles. In particular, via distributed consensus, the robots compute (a) the convex hull of the robot positions, (b) the desired direction of movement and (c) a large convex region embedded in the four dimensional position-time free space. The robots then compute, via sequential convex programming, the locally optimal parameters for the formation to remain within the convex neighborhood of the robots. The method allows for reconfiguration. Each robot then navigates towards its assigned position in the target collision-free formation via an individual controller that accounts for its dynamics. This approach is efficient and scalable with the number of robots. We present an extensive evaluation of the communication requirements and verify the method in simulations with up to sixteen quadrotors. Lastly, we present experiments with four real quadrotors flying in formation in an environment with one moving human.
Sample Efficient Learning of Path Following and Obstacle Avoidance Behavior for Quadrotors
S. Stevsic,
T. Naegeli,
J. Alonso-Mora,
O. Hilliges.
In IEEE Robotics and Automation Letters,
2018.
In this paper we propose an algorithm for the training of neural network control policies for quadrotors. The learned control policy computes control commands directly from sensor inputs and is hence computationally efficient. An imitation learning algorithm produces a policy that reproduces the behavior of a path following control algorithm with collision avoidance. Due to the generalization ability of neural networks, the resulting policy performs local collision avoidance of unseen obstacles while following a global reference path. The algorithm uses a time-free model predictive path-following controller as a supervisor. The controller generates demonstrations by following few example paths. This enables an easy to implement learning algorithm that is robust to errors of the model used in the model predictive controller. The policy is trained on the real quadrotor, which requires collision-free exploration around the example path. An adapted version of the supervisor is used to enable exploration. Thus, the policy can be trained from a relatively small number of examples on the real quadrotor, making the training sample efficient.
Vehicle Rebalancing for Mobility-on-Demand Systems with Ride-Sharing
A. Wallar,
M. van der Zee,
J. Alonso-Mora,
D. Rus.
In Proc. of the IEEE/RSJ Conf. on Robotics and Intelligent Systems (IROS),
2018.
Recent developments in Mobility-on-Demand (MoD) systems have demonstrated the potential of road vehicles as an efficient mode of urban transportation Newly developed algorithms can compute vehicle routes in real-time for batches of requests and allow for multiple requests to share vehicles. These algorithms have primarily focused on optimally producing vehicle schedules to pick up and drop off requests. The redistribution of idle vehicles to areas of high demand, known as rebalancing, on the contrary has received little attention in the context of ride-sharing. In this paper, we present a method to rebalance idle vehicles in a ride-sharing enabled MoD fleet. This method consists of an algorithm to optimally partition the fleet operating area into rebalancing regions, an algorithm to determine a real-time demand estimate for every region using incoming requests, and an algorithm to optimize the assignment of idle vehicles to these rebalancing regions using an integer linear program. Evaluation with historical taxi data from Manhattan shows that we can service 99.8% of taxi requests in Manhattan using 3000 vehicles with an average waiting time of 57.4 seconds and an average in-car delay of 13.7 seconds. Moreover, we can achieve a higher service rate using 2000 vehicles than prior work achieved with 3000. Furthermore, with a fleet of 3000 vehicles, we reduce the average travel delay by 86%, the average waiting time by 37%, and the amount of ignored requests by 95% compared to earlier work at the expense of an increased distance travelled by the fleet.
Coordination of Multiple Vessels Via Distributed Nonlinear Model Predictive Control
L. Ferranti,
R. R. Negenborn,
T. Keviczky,
J. Alonso-Mora.
In Proc. European Control Conference (ECC),
2018.
This work presents a method for multi-robot trajectory planning and coordination based on nonlinear model predictive control (NMPC). In contrast to centralized approaches, we consider the distributed case where each robot has an on-board computation unit to solve a local NMPC problem and can communicate with other robots in its neighborhood. We show that, thanks to tailored interactions (i.e., interactions designed according to a nonconvex alternating direction method of multipliers, or ADMM, scheme), the proposed solution is equivalent to solving the centralized control problem. With some communication exchange, required by the ADMM scheme at given synchronization steps, the safety of the robots is preserved, that is, collisions with neighboring robots are avoided and the robots stay within the bounds of the environment. In this work, we tested the proposed method to coordinate three autonomous vessels at a canal intersection. Nevertheless, the proposed approach is general and can be applied to different applications and robot models.
Joint Multi-Policy Behavior Estimation and Receding-Horizon Trajectory Planning for Automated Urban Driving
B. Zhou,
W. Schwarting,
D. Rus,
J. Alonso-Mora.
In Proc. IEEE Int. Conf. on Robotics and Automation (ICRA),
2018.
When driving in urban environments, an autonomous vehicle must account for the interaction with other traffic participants. It must reason about their future behavior, how its actions affect their future behavior, and potentially consider multiple motion hypothesis. In this paper we introduce a method for joint behavior estimation and trajectory planning that models interaction and multi-policy decision-making. The method leverages Partially Observable Markov Decision Processes to estimate the behavior of other traffic participants given the planned trajectory for the ego-vehicle, and Receding-Horizon Control for generating safe trajectories for the ego-vehicle. To achieve safe navigation we introduce chance constraints over multiple motion policies in the receding-horizon planner. These constraints account for uncertainty over the behavior of other traffic participants. The method is capable of running in real-time and we show its performance and good scalability in simulated multi-vehicle intersection scenarios.