Autonomous Drones for Emergency Responders
People
Funding
This project is funded by the National Police (Politie) of the Netherlands.
About the Project
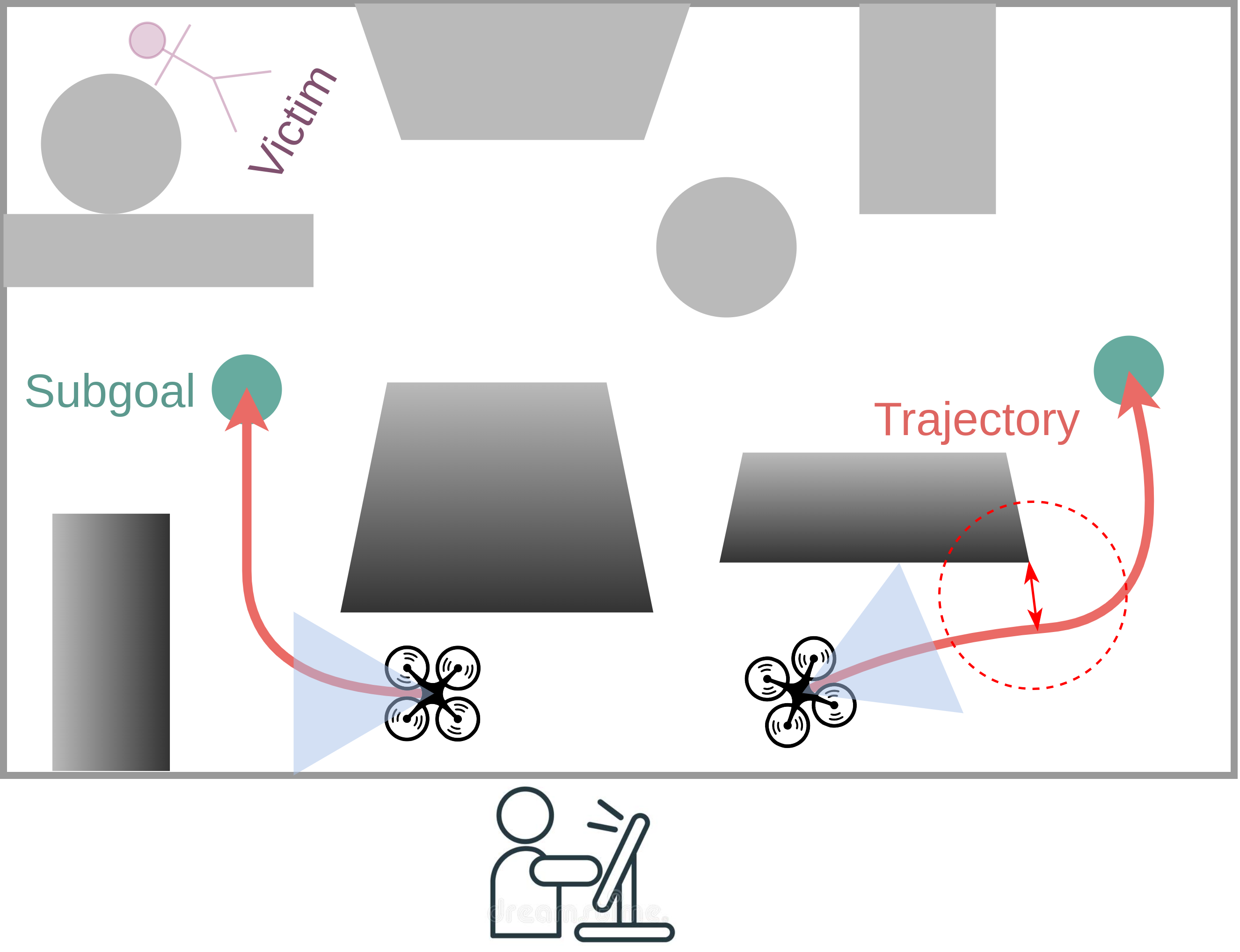
How can autonomous drones support operations of emergency responders such as the police? This project targets scenarios such as search and rescue or reconnaissance in large, unknown and potentially hazardous environments, where it can be difficult or even dangerous for policemen to operate and fulfil the task themselves. In this project we aim to enable drones to operator in such remote environments and gather information required by police operators. We develop methods to control entire teams of drones, so they can fly safely between obstacles and are robust to unexpected disturbances, and can navigate unknown environments to provide the required information.
Search missions require motion planning and navigation methods for information gathering that continuously replan based on new observations of the robot’s surroundings. Current methods for information gathering are capable of reasoning over long horizons, but they are computationally expensive. To overcome these limitations we train an information-aware policy via deep reinforcement learning, that guides a trajectory optimization planner. In particular, the policy continuously recommends a reference viewpoint to the local planner, such that the resulting collision-free trajectories lead to observations that maximize the information gain and reduce the uncertainty about the environment. In simulation tests in previously unseen environments, the proposed method consistently outperforms greedy next-best-view policies in terms of information gains and coverage time, with a reduction in execution time by three orders of magnitude.
Another contribution from this project is a novel method that aims at understanding the objectives of each agent in a multi-agent setting based on the observed interactions. These objectives can be obtained using noisy and partial state observations. This is beneficial in several scenarios where different agents need to interact with other agents in it’s environment. Consider a traffic scenario where drivers are performing lane changes. Such a setting requires a driver to understand the behavior of others as well so that a safe distance can be maintained without compromising on speed. The proposed method can identify unknown parameters of each agent’s cost function based on the observatiosn so that the future trajectories or states of each agent can be predicted directly.
Project Demonstrations
Funding & Partners
This project is funded by the National Police (Politie) of the Netherlands.

Related Publications
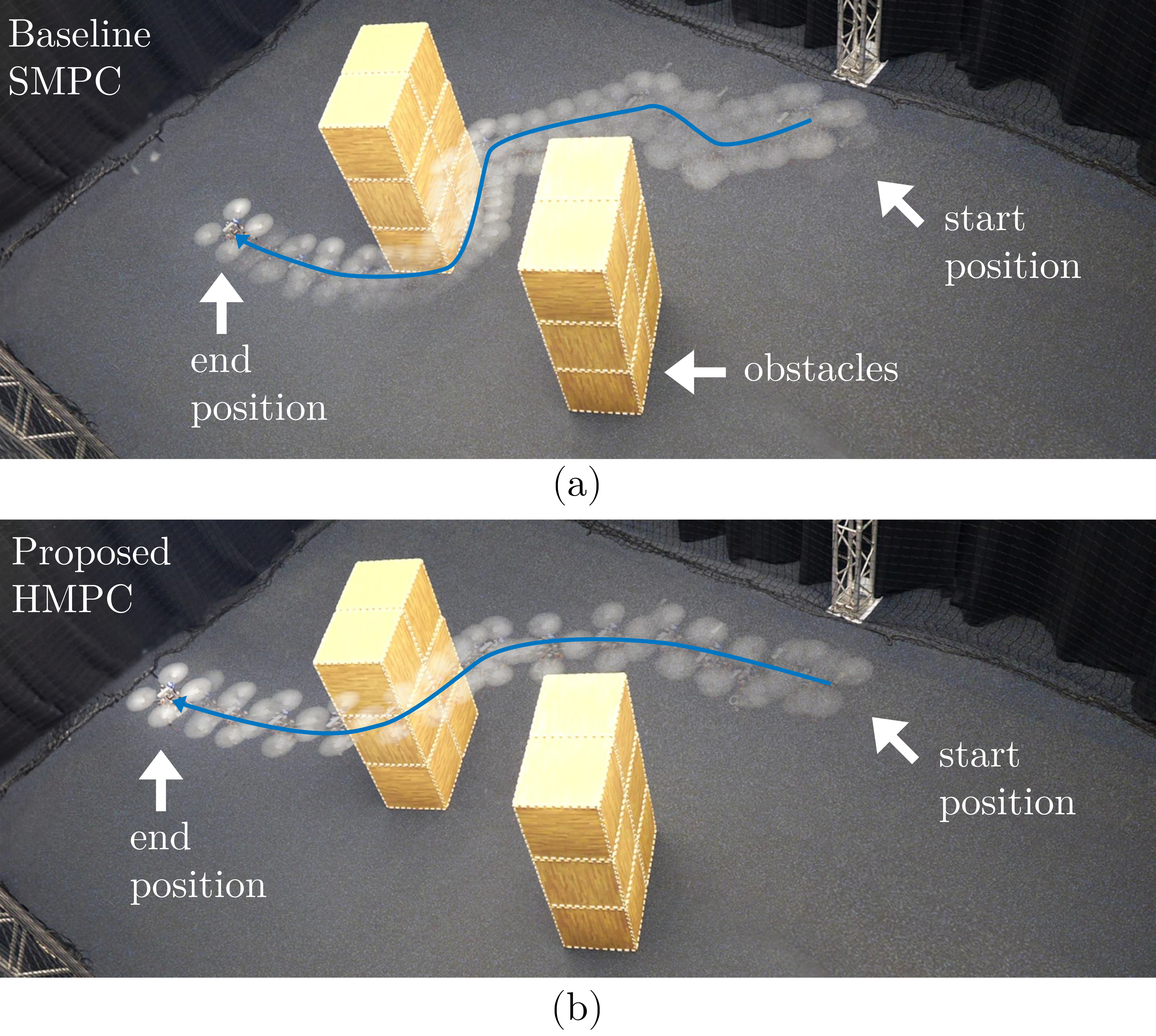
Embedded Hierarchical MPC for Autonomous Navigation
In IEEE Transactions on Robotics (T-RO),
2025.
Where to Look Next: Learning Viewpoint Recommendations for Informative Trajectory Planning
In Proc. IEEE Int. Conf. on Robotics and Automation (ICRA),
2022.
Learning Mixed Strategies in Trajectory Games
In , Proc. of Robotics: Science and Systems (RSS),
2022.