HARMONY: Assistive Robots for Healthcare
People
Funding
This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 101017008.
More LinksAbout the Project
Harmony is a Horizon 2020 project which develops assistive robotic mobile manipulation technologies for environments shared with humans, i.e., hospitals. Specifically, Harmony addresses two use cases:
- The automation of on-demand delivery tasks around the hospital
- The automation of bio-assay sample flow
Current robotic automation solutions only offer “islands of automation” where either mobility or manipulation is dealt with in isolation. Harmony aims to fill this gap in knowledge by combining both robotic mobility and manipulation modalities in complex, human-centred environments. We at AMR focus on providing adaptive task and motion planning with multiple robots in human-centred environments.
Traditionally task scheduling and planning has been decoupled from motion planning. Yet, when robots navigate in critical and dynamic environments, plans may have to be adapted online to take into account congestion and interaction with other robots and human co-workers.
We devise methods for multi-robot motion planning that schedule plans for the robots and adapt them online taking into account the priority of tasks, their associated uncertainty and the preferences and needs of human co-workers. This includes novel methods for Multi-Robot Task Assignment (MRTA) that consider uncertain environments and homogenous robot fleets. Further, we design novel multi-objective planning frameworks that can efficiently explore Pareto-optimal trade-offs. Our results include general solutions for a wide range of motion planning problems as well as specialized methods for multi-objective MRTA.
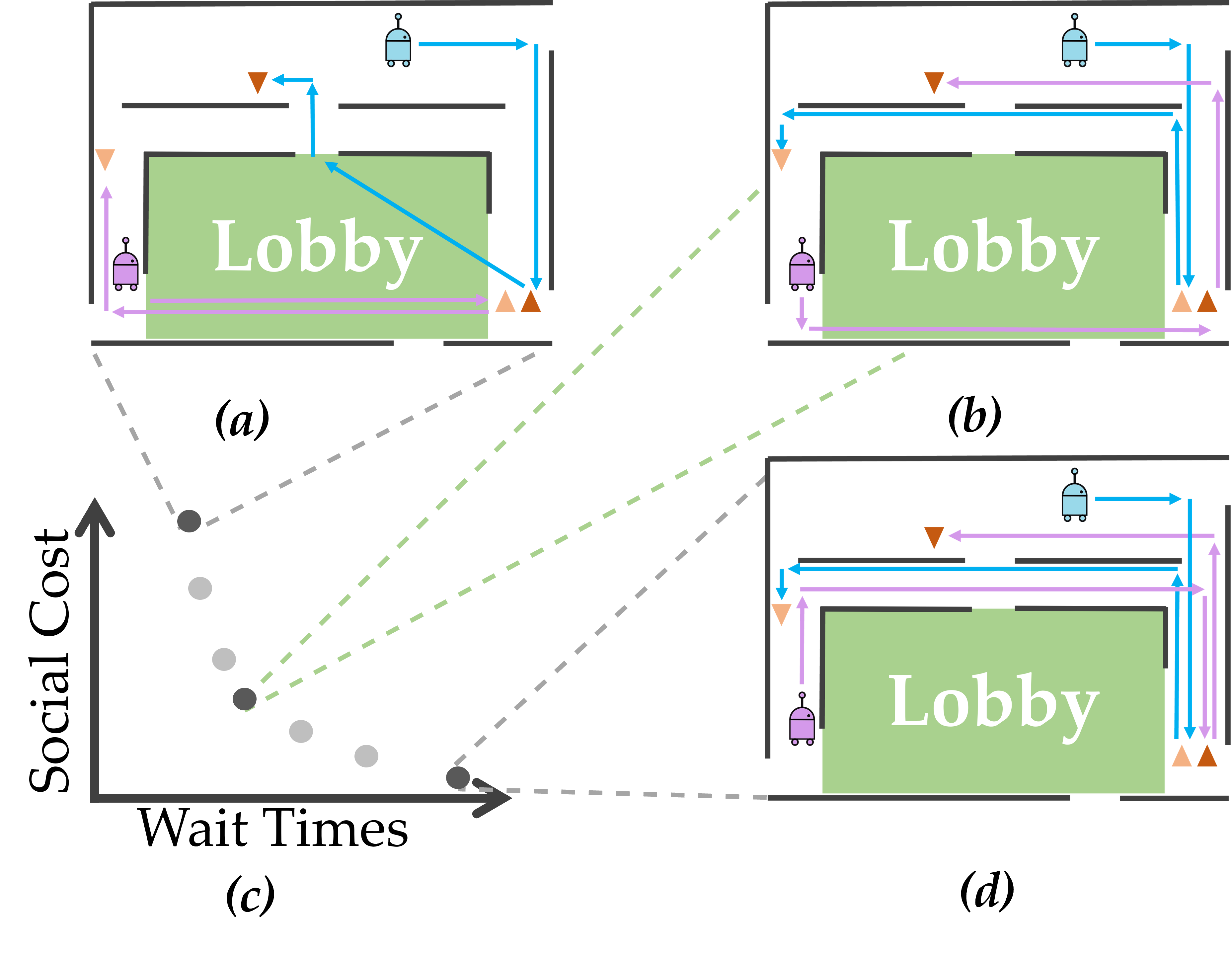
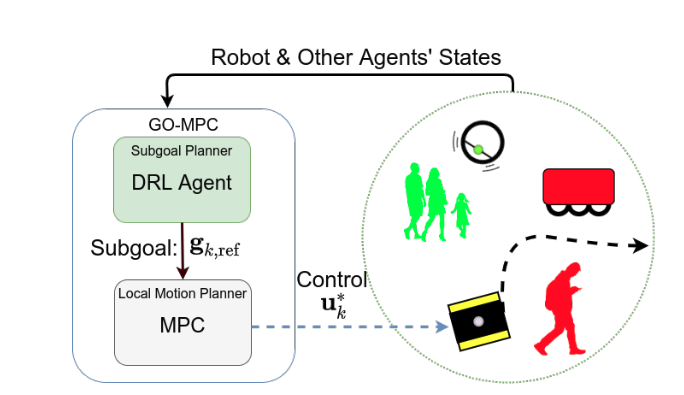
Furthermore, we develop local-motion planning approaches which do not only account for collision avoidance but also consider social interactions. We design integrated approaches for navigation as well as mobile manipulation in uncertain and dynamic environments shared with humans, which accounts for social interactions, navigation and coordination tasks, and that provides performance guarantees (in expectation).
Project Demonstrations
Partners
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 101017008.

Related Publications
SHINE: Social Homology Identification for Navigation in Crowded Environments
In International Journal of Robotics Research (IJRR),
2025.
Current-Based Impedance Control for Interacting with Mobile Manipulators
In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS),
2024.

Learning Social Homologies for Navigation
In Robotics: Science and Systems (RSS), Workshop on Unsolved Problems in Social Robot Navigation,
2024.
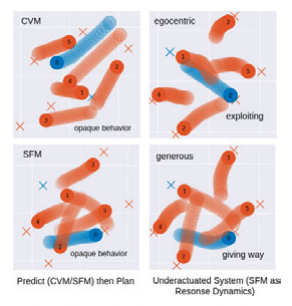
Interaction-Aware Autonomous Navigation among Pedestrians using Social Forces Response Dynamics
In Robotics: Science and Systems (RSS), Workshop on Unsolved Problems in Social Robot Navigation,
2024.
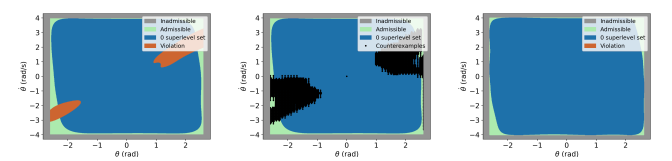
Simultaneous Synthesis and Verification of Neural Control Barrier Functions through Branch-and-Bound Verification-in-the-Loop Training
In European Control Conference (ECC),
2024.
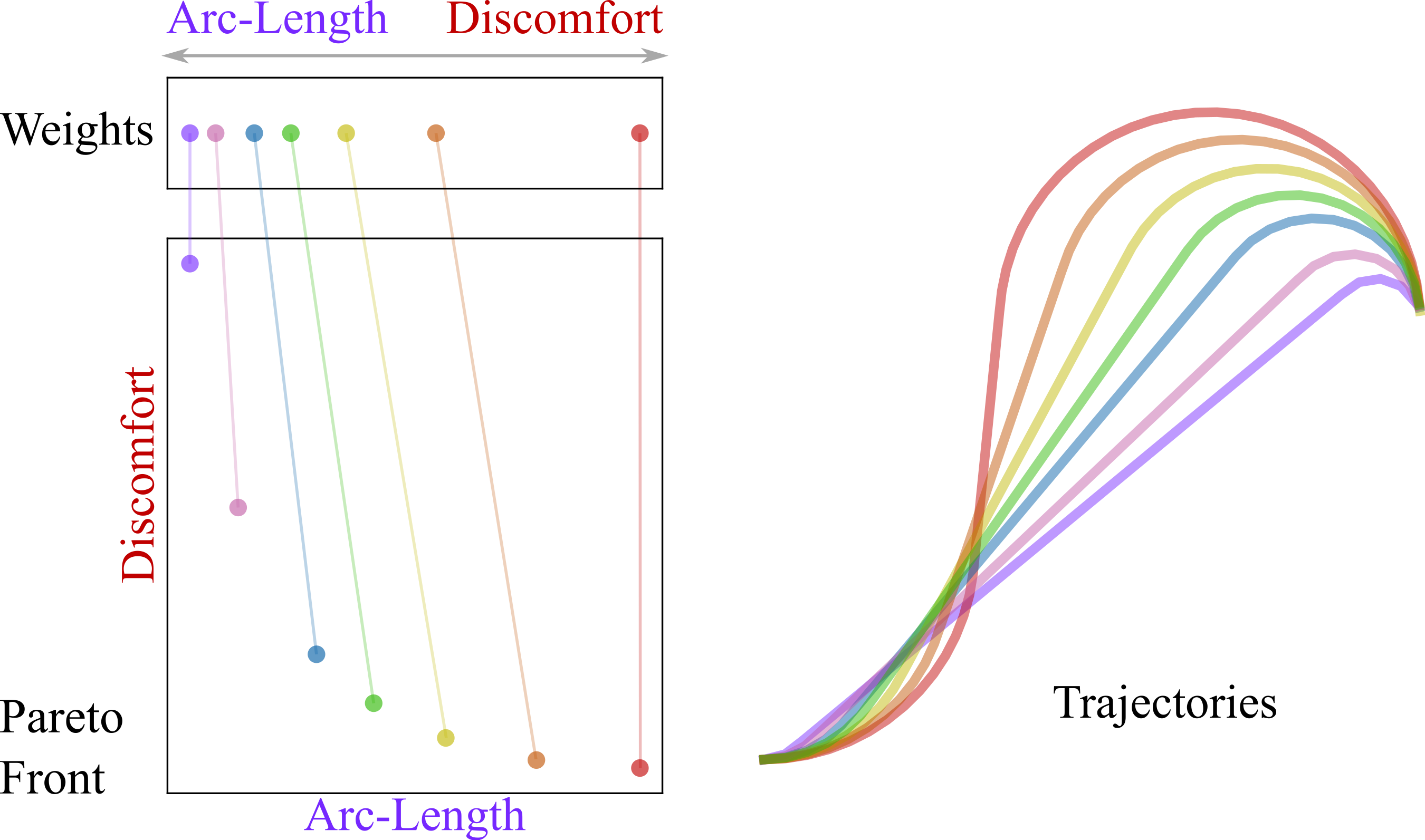
Regret-based Sampling of Pareto Fronts for Multi-Objective Robot Planning Problems
In IEEE Transaction on Robotics(T-RO),
2024.
Statistically Distinct Plans for Multi-Objective Task Assignment
In IEEE Transaction on Robotics(T-RO),
2024.
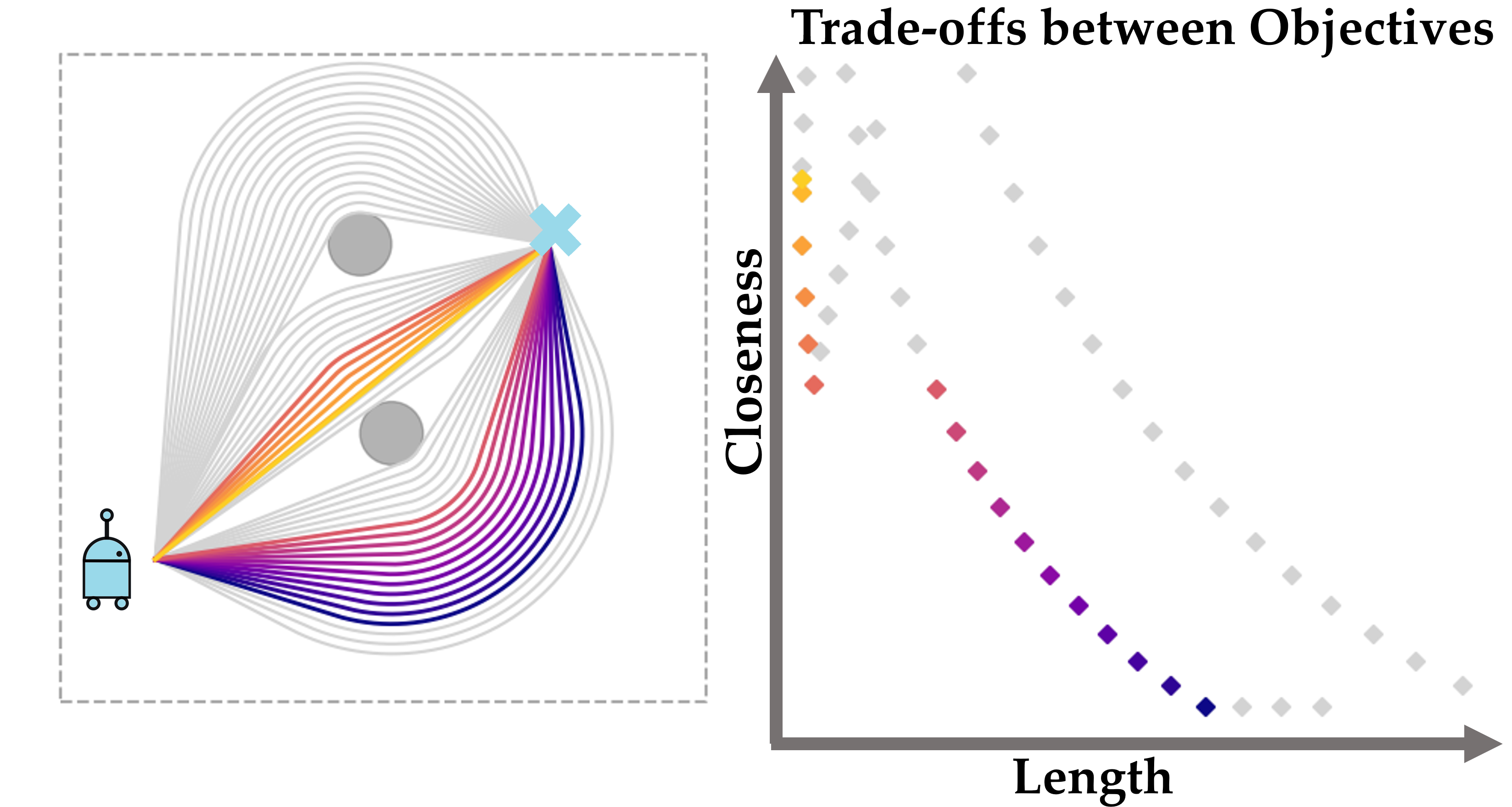
Scalarizing Multi-Objective Robot Planning Problems Using Weighted Maximization
In IEEE Robotics and Automation Letters (RA-L),
2024.
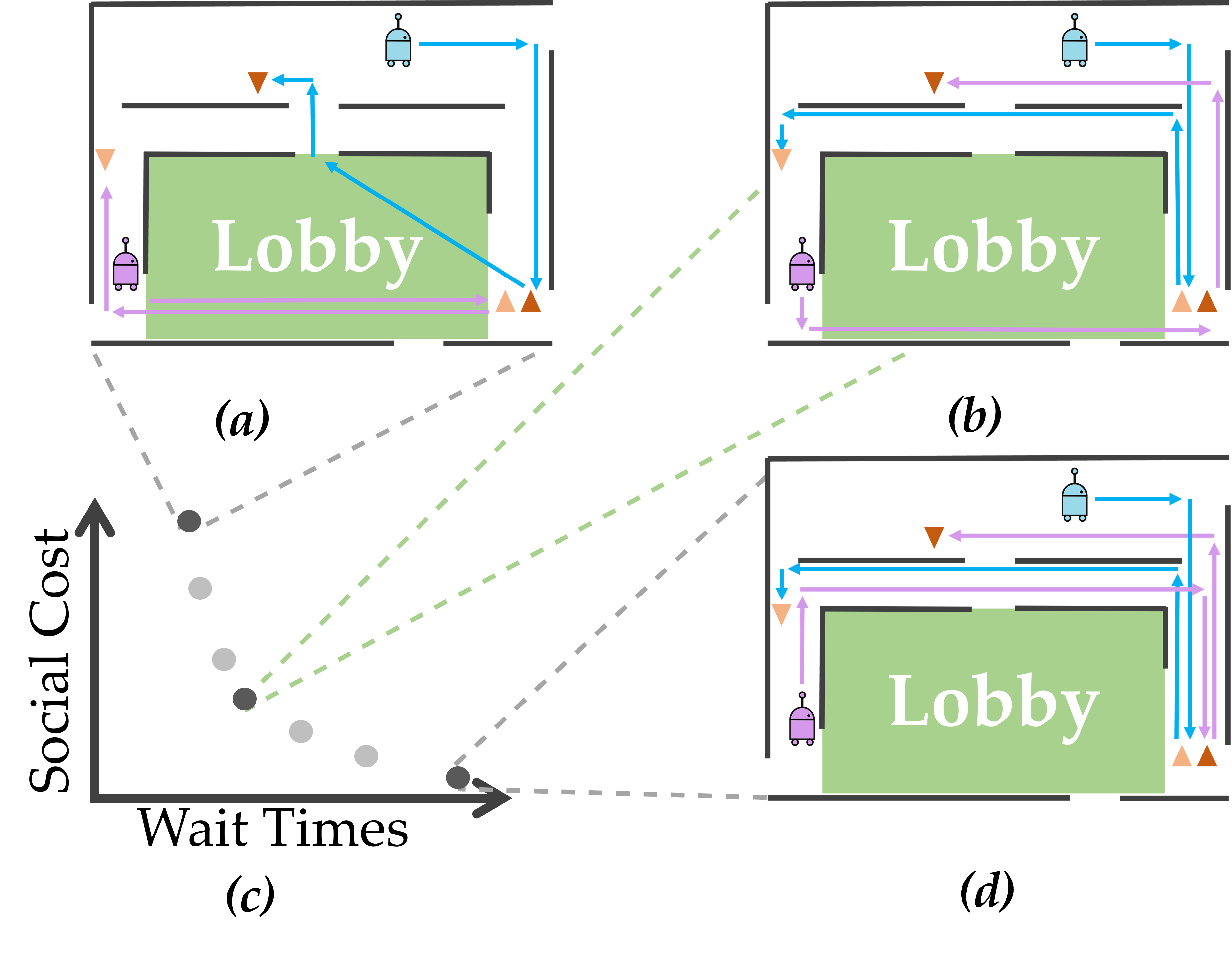
Optimizing Task Waiting Times in Dynamic Vehicle Routing
In IEEE Robotics and Automation Letters (RA-L),
2023.

Designing Heterogeneous Robot Fleets for Task Allocation and Sequencing
In Proc. IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS),
2023.
Multi-Robot Local Motion Planning Using Dynamic Optimization Fabrics
In Proc. IEEE International Symposium on Multi-Robot and Multi-Agent Systems,
2023.
Group-based Distributed Auction Algorithms for Multi-Robot Task Assignment
In IEEE Transactions on Automation Science and Engineering (T-ASE),
2023.
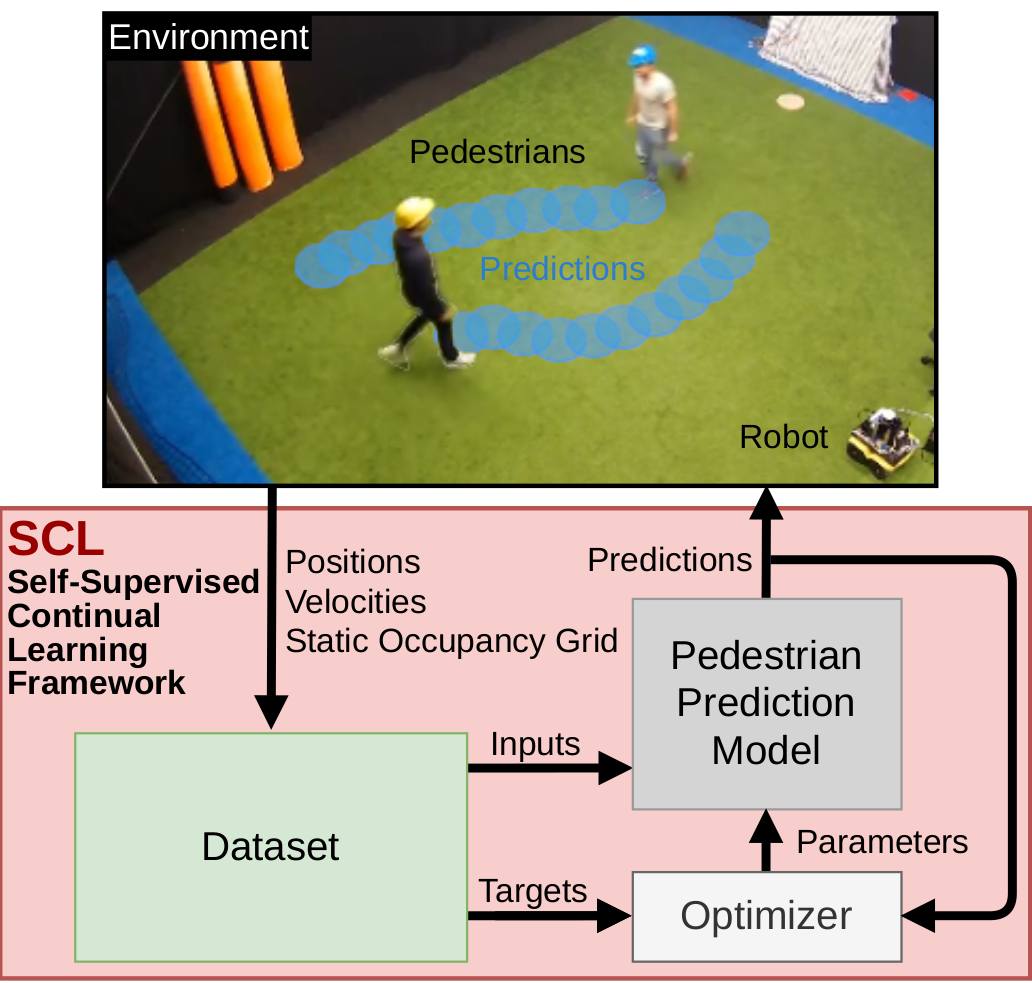
Improving Pedestrian Prediction Models with Self-Supervised Continual Learning
In , IEEE Robotics and Automation Letters (RA-L),
2022.
Do we use the Right Measure? Challenges in Evaluating Reward Learning Algorithms
In Conference on Robot Learning (CoRL),
2022.
Online Multi-Robot Task Assignment with Stochastic Blockages
In IEEE Conference on Decision and Control (CDC),
2022.
Error-Bounded Approximation of Pareto Fronts in Robot Planning Problems
In 15th Workshop on the Algorithmic Foundations of Robotics (WAFR),
2022.
Learning a Guidance Policy from Humans for Social Navigation
In Social Robot Navigation: Advances and Evaluation at IEEE International Conference on Robotics and Automation (ICRA),
2022.
Integrated Task Assignment and Path Planning for Capacitated Multi-Agent Pickup and Delivery
In , IEEE Robotics and Automation Letters (RA-L),
2021.
Where to go next: Learning a Subgoal Recommendation Policy for Navigation in Dynamic Environments
In , IEEE Robotics and Automation Letters (RA-L),
2021.