By leveraging the recently introduced geometric framework for motion planning called geometric fabrics,
our approach learns stable motion profiles while considering online whole-body collision-avoidance and joint limits.
Abstract
Using the language of dynamical systems, Imitation learning (IL) provides an intuitive and effective way of teaching stable task-space motions to robots with goal convergence. Yet, IL techniques are affected by serious limitations when it comes to ensuring safety and fulfillment of physical constraints. With this work, we solve this challenge via TamedPUMA, an IL algorithm augmented with a recent development in motion planning called geometric fabrics.
As both the IL policy and geometric fabrics describe motions as artificial second-order dynamical systems, we propose two variations where IL provide a navigation policy for geometric fabrics.
The result is a stable imitation learning strategy within which we can seamlessly blend geometrical constraints like collision avoidance and joint limits.
Beyond providing a theoretical analysis, we demonstrate TamedPUMA with simulated and real-world tasks, including a 7-DoF manipulator.
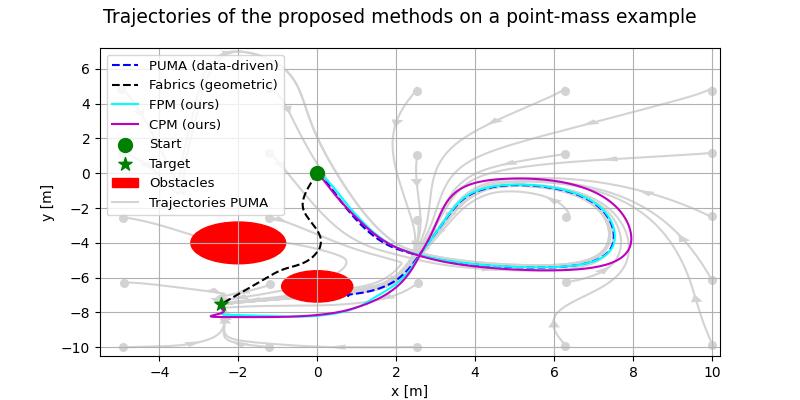
In Fig. 1 , trajectories are shown of a 2D point-mass example for the proposed methods, alongside baselines of geometric fabrics[1, 2] with a manually designed potential function, and PUMA[3]. The purely data-driven method PUMA follows the motion profile as learned from demonstrations, although it has no notion of obstacle avoidance or other physical constraints. The proposed methods, FPM and CPM, successfully follow the desired motion profile of PUMA, while avoiding collisions with the obstacles. In contrast, geometric fabrics are unable to follow the desired motion profile.
Experiment: Tomato picking with a 7-DoF manipulator
Demonstrating the tomato-picking task
Results of the tomato-picking task with TamedPUMA
Via TamedPUMA, PUMA is enhanced for safe and stable navigation, while accounting for whole-body collision avoidance and joint limits. We propose two variations, the Forcing Policy Method (FPM) and the Compatible Potential Method (CPM).
Note that the robot-hand is controlled via a binary open-close when the target pose is reached within the tolerance.
FPM
In the FPM, convergence to the goal is not guaranteed, but works well in practice.
CPM
CPM provides a stronger notion of goal convergence than the FPM. In practice, the performance is similar to FPM.
An out-of-distribution scenario
When an obstacle forces the robot towards a pose far from the demonstrations, TamedPUMA recovers and reaches the goal.
Human disturbances
When a human disturbs the robot, TamedPUMA can recover and converges to the goal.
Experiment: Pouring a liquid
Avoiding the helmet
TamedPUMA avoids collisions with the helmet while performing a learned pouring task.
Online goal changes
Using TamedPUMA, the goal can be changed online.
Comparison with geometric fabrics and PUMA
Note: The following videos might not display in Chrome, but they do render in Firefox, we are addressing this problem!
Geometric Fabrics
Fabrics causes a deadlock scenario with two obstacles representing the side of the box.
TamedPUMA (ours)
The DNN encodes an intuitive movement to avoid the side of the box.
PUMA
Via PUMA, the demonstrated movement is learned while ensuring goal converge. Obstacle avoidance and physical constraints are NOT considered.
TamedPUMA (ours)
Via TamedPUMA, PUMA is enhanced for safe and stable navigation. Whole-body collision avoidance and joint limits are incorporated.
Appendix - Supplementary material on TamedPUMA
This PDF contains additional theoretical analysis on the proofs,
differential mappings and pseudo-code for TamedPUMA.
This link guides to the webpage with theoretical details on TamedPUMA, as also explored in Section 1 of the pdf.
Learned dynamical systems are often trained in a normalized position and orientation space. To obtain the correct inputs for the network from joint positions and velocities, we require forward kinematics and transformations with respect to Euclidian and non-Euclidian spaces. The output of the network is mapped to a joint acceleration via a pullback operation, as in Eq. (6) in the paper.
Section 2 in the PDF explores the required differential mappings of PUMA to map these inputs and outputs of the DNN.
Pseudo-code of the algorithm can also be found in the Section 3 of the document.
Limitations
One limitation of TamedPUMA is that its optimization is conducted separately from fabrics. Consequently, because physical constraints are overlooked during training, it is still possible to obtain infeasible trajectories in the real system, especially when starting from states far from the support of the demonstration data. In such cases, PUMA might find solutions that lead to TamedPUMA reaching zero velocity, due to the fabrics component, in states other than the goal state $\vec{x}_{\textrm{g}}$.
Furthermore, this approach alters the behavior of the learned system when PUMA is integrated with fabrics, which, in some cases, may cause undesired deviations in the system's behavior.
The DNN provides a trajectory leading to an undesirable configuration, as PUMA is unaware of the physical limitations.
Human errors ...
Specifications of the DNN by PUMA
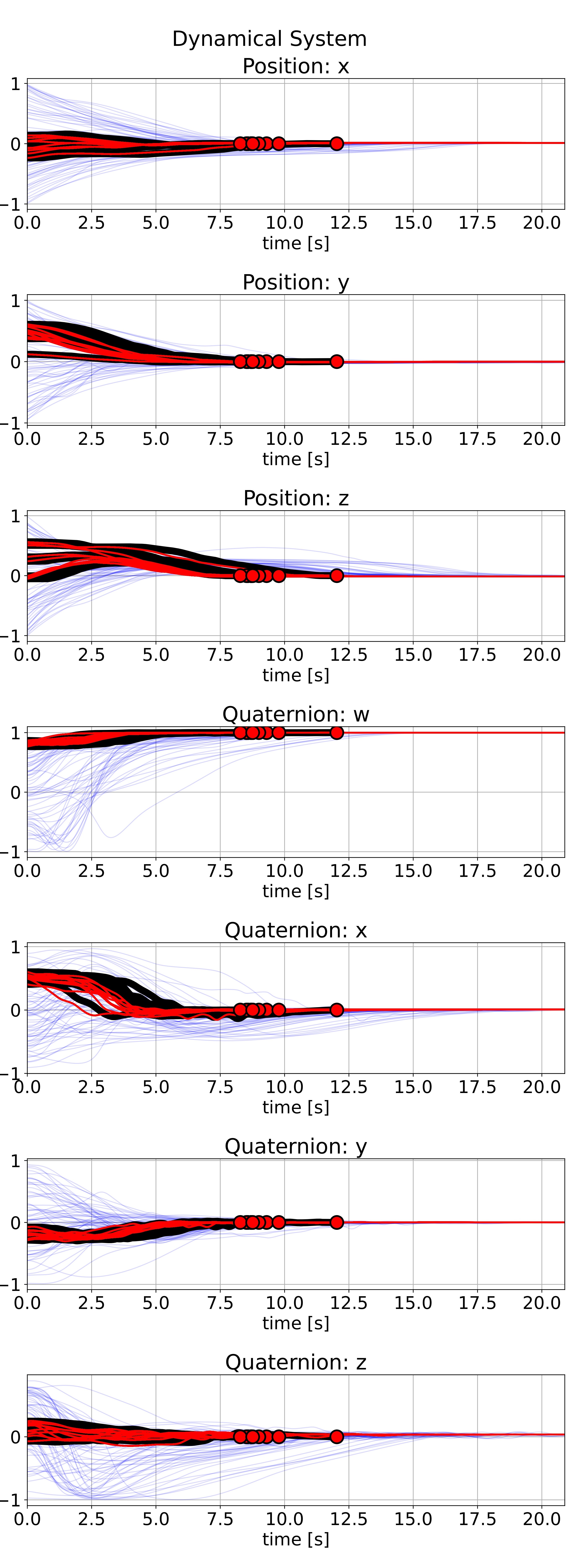
Table 1 contains specifications of the trained DNN for the tomato-picking task and pouring task. The network provides a second-order dynamical system where positions are trained over a Euclidian space and orientations over a spherical space. An illustration of the performance is provided in
Figure 3 at 5000 iterations. This shows the convergence to goal and the closeness of the solutions to the demonstrated motion profile by the user. A DNN with 5000 iterations takes 9 minutes to train on a standard laptop (i7-12700H) and 0.6 $\pm$ 0.1 ms to request an action from the DNN online.
Table 1. Hyperparameters of PUMA for a second-order dynamical system learning a pose, e.g. position and orientation.
Hyperparameter
Value (tomato-picking)
Value (pouring)
PUMA
Stability loss margin ($m$)
1e-6
1e-6
Triplet imitation loss weight ($\lambda$)
1.0
1.0
Window size imitation ($\mathcal{H}^i$)
13
13
Window size stability ($\mathcal{H}^s$)
2
2
Batch size imitation ($\mathcal{B}^i$)
800
800
Batch size stability ($\mathcal{B}^s$)
800
800
Neural Network
Optimizer
Adam
Adam
Number of iterations
40000
27000
Learning rate
1e-4
1e-4
Activation function
GELU
GELU
Num. layers ($\varphi_{\theta}, \rho_\theta$)
(3, 3)
(3, 3)
Layer normalization
yes
yes
Specifications of the joint impedance controller
The joint impedance controller is updated at 1000 Hz, while TamedPUMA runs at 30 Hz on the real-world KUKA iiwa 14. Detailed settings of the joint impedance controller are indicated in Table 2.
Table 2. Parameters of the joint impedance controller
Parameters
Value
Joint impedance controller
Stiffness position
[600, 600, 500, 450, 180, 100, 40]
Damping position
[61, 61, 33, 32, 20, 12, 7]
Stiffness velocity
[950, 950, 850, 680, 290, 170, 85]
Damping velocity
[61, 61, 33, 32, 18, 11, 7]
Figure 3. Performance of the DNN trained via PUMA where all states are normalized. The demonstrations are indicated in black, the trajectories generated by the DNN for the same initial poses as the demonstrations are given in red, and trajectories from randomly sampled initial conditions are indicated in blue.
References
Ratliff, Nathan, and Van Wyk, Karl. (2023). "Fabrics: A Foundationally Stable Medium for Encoding Prior Experience." arXiv preprint arXiv:2309.07368.
Ratliff, Nathan D., Van Wyk, Karl, Xie, Mandy, Li, Anqi, and Rana, Muhammad Asif. (2020). "Optimization fabrics." arXiv preprint arXiv:2008.02399.
Pérez-Dattari, Rodrigo, Della Santina, Cosimo and Kober, Jens. (2024). "Deep metric imitation learning for stable motion primitives." Advanced Intelligent Systems.
Related Publications
Pushing Through Clutter With Movability Awareness of Blocking Obstacles
Joris J. Weeda,
Saray Bakker,
Gang Chen,
Javier Alonso-Mora.
In IEEE Int. Conf. on Robotics and Automation (ICRA), 2025.
Navigation Among Movable Obstacles (NAMO) poses a challenge for traditional path-planning methods when obstacles block the path, requiring push actions to reach the goal. We propose a framework that enables movability-aware planning to overcome this challenge without relying on explicit obstacle placement. Our framework integrates a global Semantic Visibility Graph and a local Model Predictive Path Integral (SVG-MPPI) approach to efficiently sample rollouts, taking into account the continuous range of obstacle movability. A physics engine is adopted to simulate the interaction result of the rollouts with the environment, and generate trajectories that minimize contact force. In qualitative and quantitative experiments, SVG-MPPI outperforms the existing paradigm that uses only binary movability for planning, achieving higher success rates with reduced cumulative contact forces.
Globally-Guided Geometric Fabrics for Reactive Mobile Manipulation in Dynamic Environments
T. Merva,
S. Bakker,
M. Spahn,
D. Zhao,
I. Virgala,
J. Alonso-Mora.
In IEEE Robotics and Automation Letters (RA-L), 2025.
Mobile manipulators operating in dynamic environments shared with humans and robots must adapt in real time to environmental changes to complete their tasks effectively. While global planning methods are effective at considering the full task scope, they lack the computational efficiency required for reactive adaptation. In contrast, local planning approaches can be executed online but are limited by their inability to account for the full task’s duration. To tackle this, we propose Globally-Guided Geometric Fabrics (G3F), a framework for real-time motion generation along the full task horizon, by interleaving an optimization-based planner with a fast reactive geometric motion planner, called Geometric Fabrics (GF). The approach adapts the path and explores a multitude of acceptable target poses, while accounting for collision avoidance and the robot’s physical constraints. This results in a real-time adaptive framework considering whole-body motions, where a robot operates in close proximity to other robots and humans. We validate our approach through various simulations and real-world experiments on mobile manipulators in multi-agent settings, achieving improved success rates compared to vanilla GF, Prioritized Rollout Fabrics and Model Predictive Control.
Safe and stable motion primitives via imitation learning and geometric fabrics
Saray Bakker,
Rodrigo Pérez-Dattari,
Cosimo Della Santina,
Wendelin Böhmer,
Javier Alonso-Mora.
In Robotics: Science and Systems, Workshop on Structural Priors as Inductive Biases for Learning Robot Dynamics, 2024.
Using the language of dynamical systems, Imitation learning (IL) provides an intuitive and effective way of teaching stable task-space motions to robots with goal convergence. Yet, these techniques are affected by serious limitations when it comes to ensuring safety and fulfillment of physical constraints. With this work, we propose to solve this challenge via TamedPUMA, an IL algorithm augmented with a recent development in motion planning called geometric fabrics. We explore two variations of this approach, which we name the forcing policy method and the compatible potential method. Making these combinations possible requires two enabling factors: the possibility of learning second-order dynamical systems by imitation and the availability of a potential function that is compatible with the learned dynamics. In this paper, we show how these conditions can be met when using an IL strategy called PUMA. The result is a stable imitation learning strategy within which we can seamlessly blend geometrical constraints like collision avoidance and joint limits. Beyond providing a theoretical analysis, we demonstrate TamedPUMA with simulated and real-world tasks, including a 7-degree-of-freedom manipulator that is trained to pick a tomato from a crate in the presence of obstacles.
Reactive grasp and motion planning for adaptive mobile manipulation among obstacles
Tomas Merva,
Saray Bakker,
Max Spahn,
Ivan Virgala,
Javier Alonso-Mora.
In Robotics: Science and Systems, Workshop on Frontiers of Optimization for Robotics, 2024.
Mobile manipulators are susceptible to situations in which the precomputed grasp pose is not reachable as the result of conflicts between collision avoidance behaviour and the manipulation task. In this work, we address this issue by combining real-time grasp planning with geometric motion planning for decentralized multi-agent systems, referred to as Reactive Grasp Fabrics (RGF). We optimize the precomputed grasp pose candidate to account for obstacles and the robot's kinematics. By leveraging a reactive geometric motion planner, specifically geometric fabrics, the grasp optimization problem can be simplified, resulting in a fast, adaptive framework that can resolve deadlock situations in pick-and-place tasks. We demonstrate the robustness of this approach by controlling a mobile manipulator in both simulation and real-world experiments in dynamic environments.
Multi-Robot Local Motion Planning Using Dynamic Optimization Fabrics
Saray Bakker,
Luzia Knoedler,
Max Spahn,
Wendelin Boehmer,
Javier Alonso-Mora.
In Proc. IEEE International Symposium on Multi-Robot and Multi-Agent Systems, 2023.
In this paper, we address the problem of real-time motion planning for multiple robotic manipulators that operate in close proximity. We build upon the concept of dynamic fabrics and extend them to multi-robot systems, referred to as Multi-Robot Dynamic Fabrics (MRDF). This geometric method enables a very high planning frequency for high-dimensional systems at the expense of being reactive and prone to deadlocks. To detect and resolve deadlocks, we propose Rollout Fabrics where MRDF are forward simulated in a decentralized manner. We validate the methods in simulated close-proximity pick-and-place scenarios with multiple manipulators, showing high success rates and real-time performance.
Group-based Distributed Auction Algorithms for Multi-Robot Task Assignment
Xiaoshan Bai,
Andres Fielbaum,
Maximilian Kronmuller,
Luzia Knoedler,
Javier Alonso-Mora.
In IEEE Transactions on Automation Science and Engineering (T-ASE), 2023.
This paper studies the multi-robot task assignment problem in which a fleet of dispersed robots needs to efficiently transport a set of dynamically appearing packages from their initial locations to corresponding destinations within prescribed time-windows. Each robot can carry multiple packages simultaneously within its capacity. Given a sufficiently large robot fleet, the objective is to minimize the robots' total travel time to transport the packages within their respective time-window constraints. The problem is shown to be NP-hard, and we design two group-based distributed auction algorithms to solve this task assignment problem. Guided by the auction algorithms, robots first distributively calculate feasible package groups that they can serve, and then communicate to find an assignment of package groups. We quantify the potential of the algorithms with respect to the number of employed robots and the capacity of the robots by considering the robots' total travel time to transport all packages. Simulation results show that the designed algorithms are competitive compared with an exact centralized Integer Linear Program representation solved with the commercial solver Gurobi, and superior to popular greedy algorithms and a heuristic distributed task allocation method.
Integrated Task Assignment and Path Planning for Capacitated Multi-Agent Pickup and Delivery
Z. Chen,
J. Alonso-Mora,
X. Bai,
D. D. Harabor,
P. J. Stuckey.
In , IEEE Robotics and Automation Letters (RA-L), 2021.
Multi-agent Pickup and Delivery (MAPD) is a challenging industrial problem where a team of robots is tasked with transporting a set of tasks, each from an initial location and each to a specified target location. Appearing in the context of automated warehouse logistics and automated mail sortation, MAPD requires first deciding which robot is assigned what task (i.e., Task Assignment or TA) followed by a subsequent coordination problem where each robot must be assigned collision-free paths so as to successfully complete its assignment (i.e., Multi-Agent Path Finding or MAPF). Leading methods in this area solve MAPD sequentially: first assigning tasks, then assigning paths. In this work we propose a new coupled method where task assignment choices are informed by actual delivery costs instead of by lower-bound estimates. The main ingredients of our approach are a marginal-cost assignment heuristic and a meta-heuristic improvement strategy based on Large Neighbourhood Search. As a further contribution, we also consider a variant of the MAPD problem where each robot can carry multiple tasks instead of just one. Numerical simulations show that our approach yields efficient and timely solutions and we report significant improvement compared with other recent methods from the literature.
Anticipatory Vehicle Routing for Same-Day Pick-up and Delivery using Historical Data Clustering
J. van Lochem,
M. Kronmueller,
P. van 't Hof,
J. Alonso-Mora.
In Proc. IEEE Int. Conf. on Intelligent Transportation Systems (ITSC), 2020.
In this paper we address the problem of same-day pick-up and delivery where a set of tasks are known a priori and a set of tasks are revealed during operation. The vehicle routes are precomputed based on the known and predicted requests and adjusted online as new requests are revealed. We propose a novel anticipatory insertion method which incorporates a set of predicted requests to beneficially adjust the routes of a fleet of vehicles in real-time. Requests are predicted based on historical data, which is clustered in advance. We exploit inherent patterns of the demand, which are captured by historical data and include them in a dynamic vehicle routing solver based on heuristics and adaptive large neighborhood search. The proposed method is evaluated using numerical simulations on a variety of real-world problems with up to 1655 requests per day. Their degree of dynamism ranges from 0.70 to 0.93. These instances represent dynamic multi-depot pickup and delivery problems with time windows. The method has shown to require less driven kilometers than comparable methods.